


K Nearest Neighbors Algorithm (KNN)
Everything you need to know about k nearest neighbors algorithm


KNN means K Nearest Neighbor Algorithm. KNN is the simplest supervised machine learning algorithm mostly used for classification of data. Before moving on to KNN, let's look at machine learning briefly and the category that KNN falls under.
Machine learning (ML) is the study of computer algorithms that improve automatically through experience and data sets given. Machine learning algorithms build a model based on sample data, known as "training data", in order to make predictions or decisions without being explicitly programmed to do so. Nowadays, machine learning keeps solving on a different fields category problems such as: Computational Finance, Image Processing and Computer Vision, Computational Biology, Energy Production, Automotive, Aerospace, and Manufacturing, Natural Language Processing (NLP). Nowadays, These techniques find hidden patterns or intrinsic structures in data. it helps us to generate insight and help us to make better decisions and predictions. In Machine Learning models it allow the user to make predictions from the past DATA available.
Below is the illustration of how to represent the process between machine learning algorithm, input and process.

There are two types of machine learning algorithm techniques. The two techniques are listed below.
- Supervised learning
- Unsupervised learning
Supervised Learning Techniques: These are the techniques developed to predict model based on both input and output data.
Unsupervised Learning Techniques: These techniques finds hidden patterns or intrinsic structures in data.
In this article we are going to focused on supervised Learning Techniques. Under these supervised learning techniques, we have the following categories:
- Classifications
- Regression
Classification: Classification techniques helps in predicting discrete responses. For example, a simple algorithm that helps machine to be able to differentiate between cat and a dog. Under this we have several algorithms such as:
- K Nearest Neighbors Algorithm (KNN)
- Naive bayes Algorithm
- Decision Trees and so on
Regression: Regression Techniques helps in predicting continuous responses. For example, Changes in temperature from time to time. Under this techniques we have the following algorithms.
- Linear model
- Non Linear model
- Regularizations and so on
For this tutorial we will be focusing on a popular classification algorithm called KNN (K Nearest Neighbors Algorithm). i will be given an answer to the following questions.
- What is KNN ? Why do we need KNN ?
- How do we choose the ''K'' factor ? How do KNN algorithms work ?
- When do we use KNN ?
- What are the limitations of KNN Algorithm ?
What is KNN & Why do we need KNN ?
KNN simply means K Nearest Neighbor Algorithm, This algorithm is based on feature of the dataset similarity. KNN can help to do easy classifier.

KNN is the simplest supervised machine learning algorithm mostly used for classification of data, KNN classifies a data points based on how its neighbors are classified. KNN stores all available cases based on a similarity measure. K in KNN is a parameter that refers to the number of the neighbor to include in the majority voting process.
KNN is a lazy learning algorithm : KNN is a lazy learning algorithm because it does not have a specialized training phase and uses all the data for training during classification.
KNN is a non parametric learning algorithm : KNN is non parametric because it does not assume anything about the underlying data.
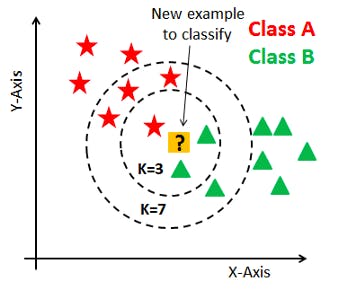
How Do We Choose The K Factor? & How does the KNN algorithm works
KNN is based on feature similarity. Choosing the right value of K is a process called parameter turning and it is important for better accuracy. These are the steps to follow to predict and to know how the KNN algorithm works.
Step 1: For implementing any algorithm, We need a data set. We must load data set. We can get a sample dataset from Kaggle.com
Data Set: a collection of related sets of information that is composed of separate elements but can be manipulated as a unit by a computer.
Step 2: We need to choose the value k i.e the nearest data point k can be integer. Odd number of K is selected to avoid the confusion between two classes of DATA.
Step 3: For each point that exists the following must be performed.
- Calculate the distance between the two point, Distance can easily be detected/calculated using the EUCLIDEAN Distance
Euclidean Distance: The Euclidean distance between two points in Euclidean space is the length of a line segment between the two points. It can be calculated from the Cartesian coordinates of the points using the Pythagorean theorem, therefore occasionally being called the Pythagorean distance. For s single Point.
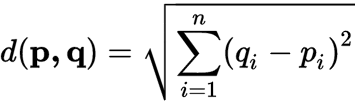
p,q = two points in Euclidean n-space
qi, pi = Euclidean vectors, starting from the origin of the space (initial point)
n = n-space
Example:-
Let consider a dataset having two variables: height(cm) & weight(kg) & each points is classified as normal or underweight.
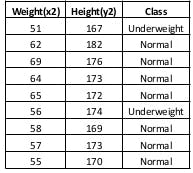


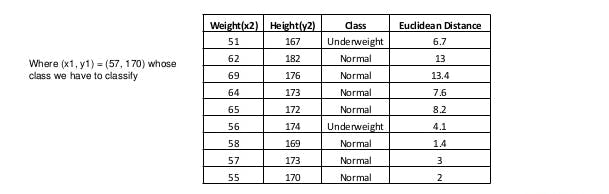 To find the nearest neighbor algorithm we calculate euclidean distance.
To find the nearest neighbor algorithm we calculate euclidean distance.
Formular
Distance between two points in the plane with coordinates (x1,y1) & (x2,y2) is given by
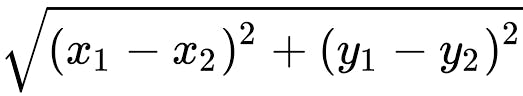
- Based on the distance value sort item in ascending order.
- It will choose the top k rows from the sorted array.
- it will assign to the test point on most frequent class of these rows.
When Do we use KNN
- When the dataset is labeled
- When the data is noise free
- KNN algorithm is used when our dataset is small.
- When dataset is small i.e KNN dosen't learn a discriminative function from a training set.
Limitation of KNN Algorithm
There are limitations to K Neighbors algorithm, the limitations are listed below.
- KNN algorithm is not advisable to use for a large dataset.
- it does not work well with a high number of dimensions.
- It is sensitive to outliers and missing values